SrpFSD: Opis morfoloških svojstava srpskog jezika |
|
Opis morfoloških svojstava srpskog jezika je preduslov za mnoge NLP
primene. Nivo detaljnosti opisa morfoloških svojstava zavisi od jezika, ali i od
namene tog opisa. Iako su uloženi značajni napori na polju standardizacije takvog
opisa, mnoge aplikacije ih ignorišu, jer im one često ne odgovaraju.
Najznačajniji standardizovani opis morfoloških svojstava srpskog jezika je
MULTEXT-East.
Srpski morfološki rečnici prostih i složenih reči su razvijeni u LADL formatu i
koriste drugačiji morfološki opis
(Krstev, 2008), ali se informacije među ovim formatima mogu razmenjivati (Krstev et al., 2004). Razvoj sistema za automatsko otkrivanje flektivnih svojstava složenih reči i fraza
(Krstev & Vitas, 2009) je zahtevao još jednu, nešto sveobuhvatniju formalizaciju morfiloških svojstava, tako da se započelo sa razvojem sveobuhvatnog opisa koji bi bio standardizovan i koji bi mogao da se jednostavno transformiše u bilo koji drugi oblik za različite primene.
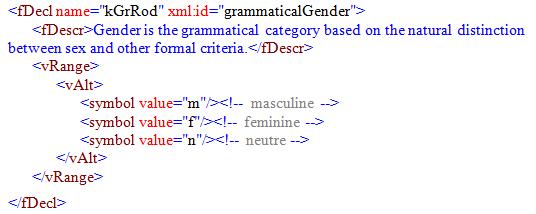
Na primer, deklaracija za gramatički rod je:
Opisi drugih vrsta reči sadrže više ograničenja, na primer brojevi sadrže osam ograničenja, a zamenice šest. TEI preporuke (TEI: P5) odgovaraju ISO 24610 standardu što je omogućilo validaciju SrpFSD. Koristeći Web interfejs alata Roma je kreirana šema koja kombinuje više modula: core tei, header, textstructure, sa iso-fs modulom koji obuhvata strukture svojstava. Pridruživanje kreirane šeme dokumentu SrpFSD je omogućilo stalnu validaciju i pomoć u radu. U softveru WS4LR (sada Leximir) se SrpFSD koristi za automatsko otkrivanje flektivnih svojstava složenih reči i fraza. Zajedno sa sistemom morfoloških rečnika prostih reči u LADL formatu i sistemom pravila struktura složenih reči uspešno se koristi za generisanje odrednica u DELAC formatu na osnovu zadate liste složenih reči. |

Kontakt: cvetana @ matf bg ac rs[Glavna strana] |